
Docker基础
Docker
Docker 是什么?
是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的 Linux 或 Windows 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。
容器与虚拟机对比: 容器相对来说较为简单运行与操作系统之上消耗资源少而虚拟机完整的模拟了一个操作系统使其消耗资源大且复杂性高不易于调试。
Docker 架构
Docker 包括三个基本概念:
- 镜像(Image): 相当于是一个 root 文件系统。比如官方镜像 ubuntu:16.04 就包含了完整的一套 Ubuntu16.04 最小系统的 root 文件系统。
- 容器(Container): 镜像和容的关系,就像是面向对象程序设计中的类和实例一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。
- 仓库(Repository): 仓库可看成一个代码控制中心,用来保存镜像。
Docker三个组件概念:
- Docker Client 是用户界面,它支持用户与 Docker Daemon 之间通信。
- Docker Daemon 运行于主机上,处理服务请求。
- Docker Index 提供镜像索引以及用户认证的功能,下载镜像的时候会先在 Docker Index 服务中做认证,然后查询镜像所在的 Docker Registry (Docker 仓库用来保存镜像) 地址并返回给 Docker 客户端。
Docker三个基本元素:
- Docker Containers 负责应用程序的运行,包括操作系统、用户添加的文件以及元数据。
- Docker Images 是一个只读模板,用来运行 Docker 容器。
- DockerFile 是文件指令集,用来说明如何自动创建 Docker 镜像。
Docker 实现原理
Docker 基于 Linux 内核的 Cgroup, Namespace, 以及 Union FS 等技术,对进程进行封装隔离,属于操作系统层面的虚拟化技术。Docker 在容器的基础上对文件系统、网络互联等进行了封装。
Namespace
Linux Namespace 是一种 Linux Kernel 提供的资源隔离方案:系统可以为进程分配不同的 Namespace 并保证不同的 Namespace 资源独立分配、进程彼此隔离,即不同的 Namespace 下的进程互不干扰。
Linux 内核代码中的 Namespace 实现:
1 | // 进程数据结构 |
Namespace 操作方法:
- clone: 创建新的系统调用时可以通过 flags 参数指定需要新建的 Namespace 类型
- setns: 该系统调用可以让调用进程加入某个已经存在的 Namespace 中:Int setns(int fd, int nstype)
- unshare: 该系统调用可以将进程移动到新的 Namespace 下: int unshare(int flags)
Namespace常用操作:
- 查看当前系统的 Namespace: lsns -t
- 查看某进程的 Namespce: ls -la /proc/
/ns/ - 进入某个 Namespace: nsenter -t
Cgroups
Cgroups (Control Groups) 是Linux下用于对一个或一组进程资源控制和监控的机制,可以对诸如 CPU 使用时间、内存、磁盘 I/O 等进程所需的资源进行限制。Cgroups 在不同的系统资源管理子系统中以层级树(Hierarchy)的方式来组织管理:每个 Cgroup 都可以包含其他的子 Cgroup,因此子 Cgroup 能使用的资源除了受本 Cgroup 配置 的资源参数限制,还受到父 Cgroup 设置的资源限制 。
1 | // css_set 是 cgroup_subsys_state 对象的集合数据结构 |
Linux-容器关系图: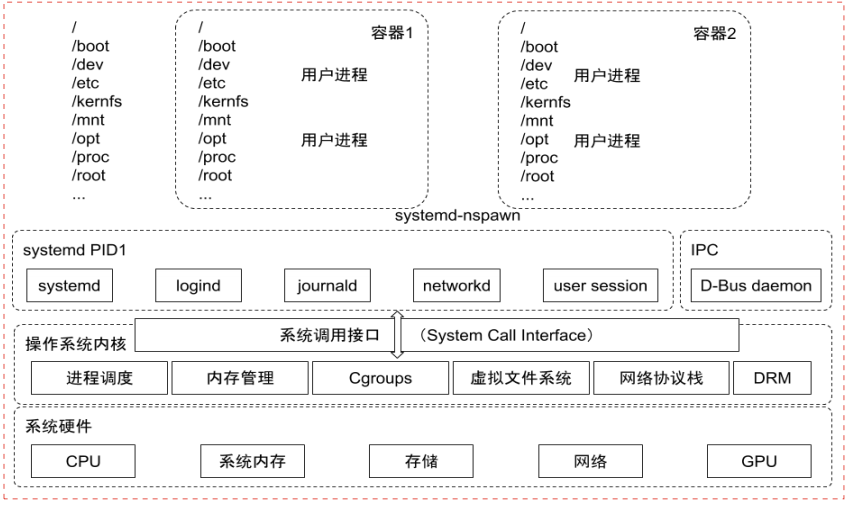
Cgroup子系统:
- blkio:这个子系统设置限制每个块设备的输入输出控制。例如:磁盘,光盘以及USB等等;
- cpu:这个子系统使用调度程序为cgroup任务提供CPU的访问;
- cpuacct:产生cgroup任务的CPU资源报告;
- cpuset:如果是多核心的CPU,这个子系统会为cgroup任务分配单独的CPU和内存;
- devices:允许或拒绝cgroup任务对设备的访问;
- freezer:暂停和恢复cgroup任务;
- memory:设置每个cgroup的内存限制以及产生内存资源报告;
- net_cls:标记每个网络包以供cgroup方便使用;
- ns:名称空间子系统;
- pid:进程标识子系统。
1 | root@Takagi:/sys/fs/cgroup# ls |
CPU 子系统
1 | root@Takagi:/sys/fs/cgroup/cpu# ls |
- cpu.shares:可出让的能获得CPU使用时间的相对值。
- cpu.cfs_period_us:cfs_period_us用来配置时间周期长度,单位为us(微秒)。
- cpu.cfs_quota_us:cfs_quota_us用来配置当前Cgroup在cfs_period_us时间内最多能使用的CPU 时间数,单位为us(微秒)。
- cpu.stat:Cgroup内的进程使用的CPU时间统计。
- nr_periods:经过cpu.cfs_period_us的时间周期数量。
- nr_throttled:在经过的周期内,有多少次因为进程在指定的时间周期内用光了配额时间而受到限制。
- throttled_time:Cgroup中的进程被限制使用CPU的总用时,单位是ns(纳秒)。
- throttled_time:Cgroup中的进程被限制使用CPU的总用时,单位是ns(纳秒)。
通过设置以上文件参数可以控制进程 CPU 资源。
CPU 子系统控制资源 demo:
- 进入到 cgroup 的 cpu 子系统
- mkdir cpudemo: 即创建一个 cgroup demo
- 运行 cpudemo.go 代码,代码中有两个空循环所以会吃两个线程资源
- 使用 top 命令可以常看 cpudemo 消耗 cpu 资源为 200% 即两核
- 将 cpudemo 进程的 pid 加入到cpudemo文件 cgroup.procs 下具体操作
echo pid > cgroup.procs - 设置 cpu.cfs_quota_us 的值与 cpu.rt_period_us 一比一将会看到 cpudemo 进程的 cpu 消耗为 100%
1 | // cpudemo.go |
Union FS
Union FS 将不同目录挂载到同一个虚拟文件系统下(unite several directories into a single virtual filesystem)的文件系统。Union FS 支持为每一个成员目录(类似GitBranch)设定readonly、readwrite和whiteout-able 权限。对readonly权限的branch 可以逻辑上进行修改(增量地, 不影响readonly部分的)。通常Union FS 有两个用途, 一方面可以将多个disk挂到同一个目录下, 另一个更常用的就是将一个readonly的branch 和一个writeable 的branch 联合在一起。
运行应用程序
运行任何应用程序,都需要有两个基本步骤:
- 构建一个镜像。
- 运行容器。
这些步骤都是从Docker Client的命令开始的。Docker Client使用的是Docker二进制文件。在基础层面上,Docker Client会告诉Docker Daemon需要创建的镜像以及需要在容器内运行的命令。当Daemon接收到创建镜像的信号后,会进行如下操作:
第一步:构建镜像
Docker Image是一个构建容器的只读模板,它包含了容器启动所需的所有信息,包括运行程序和配置数据。
每个镜像都源于一个基本的镜像,然后根据Dockerfile中的指令创建模板。对于每个指令,在镜像上创建一个新的层面。
一旦镜像创建完成,就可以将它们推送到中央registry:Docker Index,以供他人使用。然而,Docker Index为镜像提供了两个级别的访问权限:公有访问和私有访问。可以将镜像存储在私有仓库,Docker官网有私有仓库。总之,公有仓库是可搜索和可重复使用的,而私有仓库只能给那些拥有访问权限的成员使用。Docker Client可用于Docker Index内的镜像搜索。
第二步:运行容器
运行容器源于在第一步中创建的镜像。当容器被启动后,一个读写层会被添加到镜像的顶层。当分配到合适的网络和IP地址后,需要的应用程序就可以在容器中运行了。



